REM: Evaluating LLM Embodied Spatial Reasoning
through Multi‑Frame Trajectories
A benchmark for object permanence, spatial relations, temporal ordering, and counting across egocentric multi‑frame sequences in controllable 3D environments.
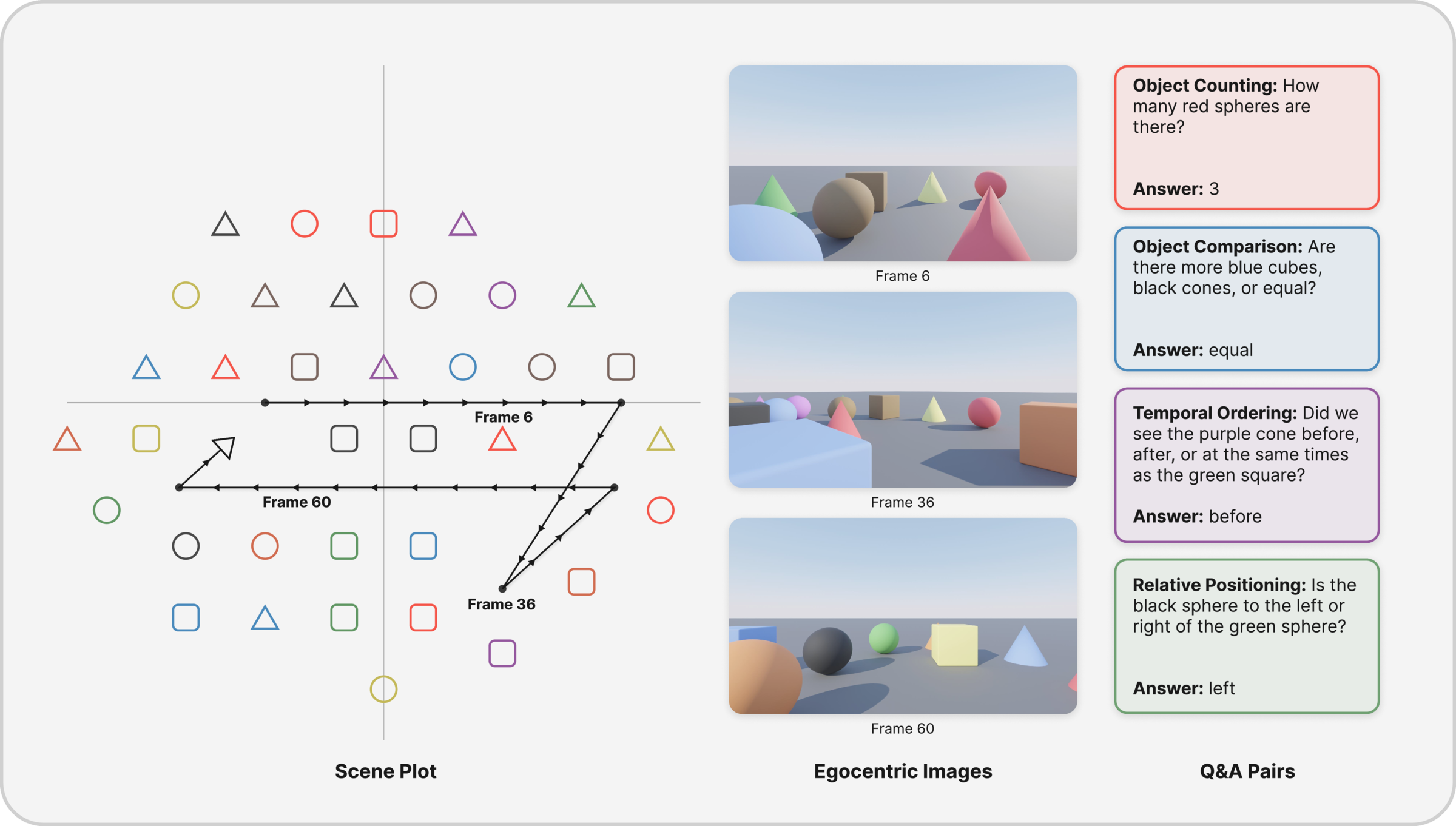
Abstract
Humans build viewpoint‑independent cognitive maps, enabling robust reasoning across navigation. Despite large‑scale video training, current MLLMs struggle with embodied spatial reasoning. REM introduces egocentric multi‑frame trajectories with explicit egomotion to evaluate object permanence & distinction, spatial relations, temporal ordering, and numerical tracking under viewpoint change. Reasoning models perform well in simple cases but degrade with congestion, duplicates, and longer horizons—far from human reliability.
Datasets
Three Blender‑generated egocentric datasets designed to isolate distinct challenges in visuospatial reasoning.
| Property | Baseline | Single Frame | Full Rotation |
|---|---|---|---|
| Num. Trajectories | 3,119 (18) | 350 | 100 |
| Total QA Pairs | 47,019 (154) | 1,289 | 2,424 |
| Trajectory Length(s) | 2, 4, 8, 16, 32, 64 (4, 8, 16, 32) | 1 | 24 |
| Object Count | 8–48 | 24–55 | 24 |
| Duplicate Count | 0–46 | 0–20 | 1–2 |
| Purpose | General capabilities | Single‑frame counting | Object distinction |
Baseline
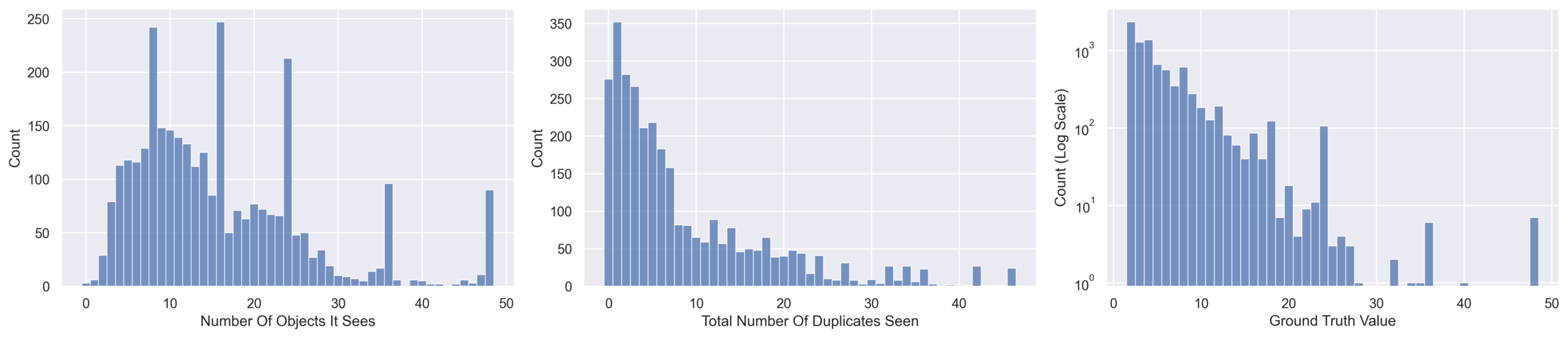
~50k QA across ~3k trajectories. Varies trajectory length, scene congestion, and duplicate rate. Tasks: counting, numerical comparison, left/right positioning, temporal ordering.

Single Frame
Isolates visual counting without frame‑to‑frame tracking, disentangling perception vs. identity maintenance.
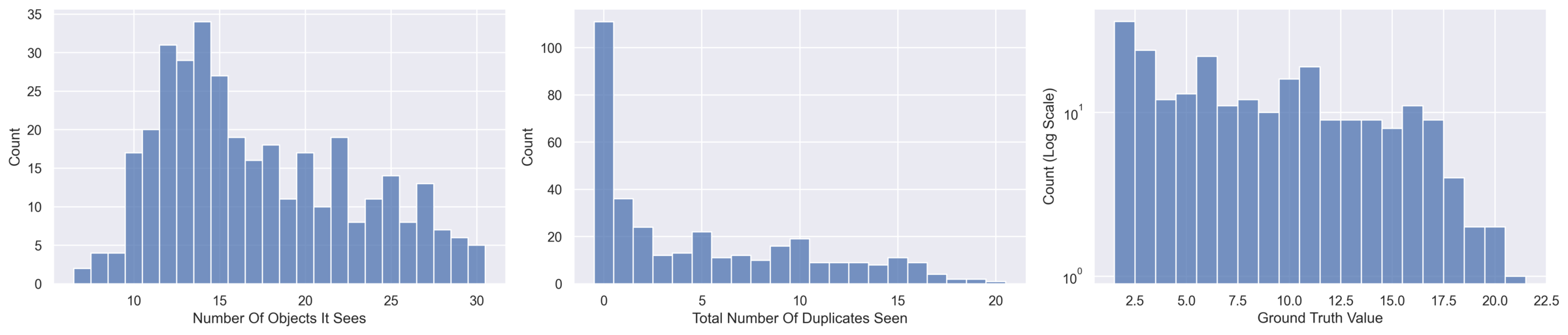
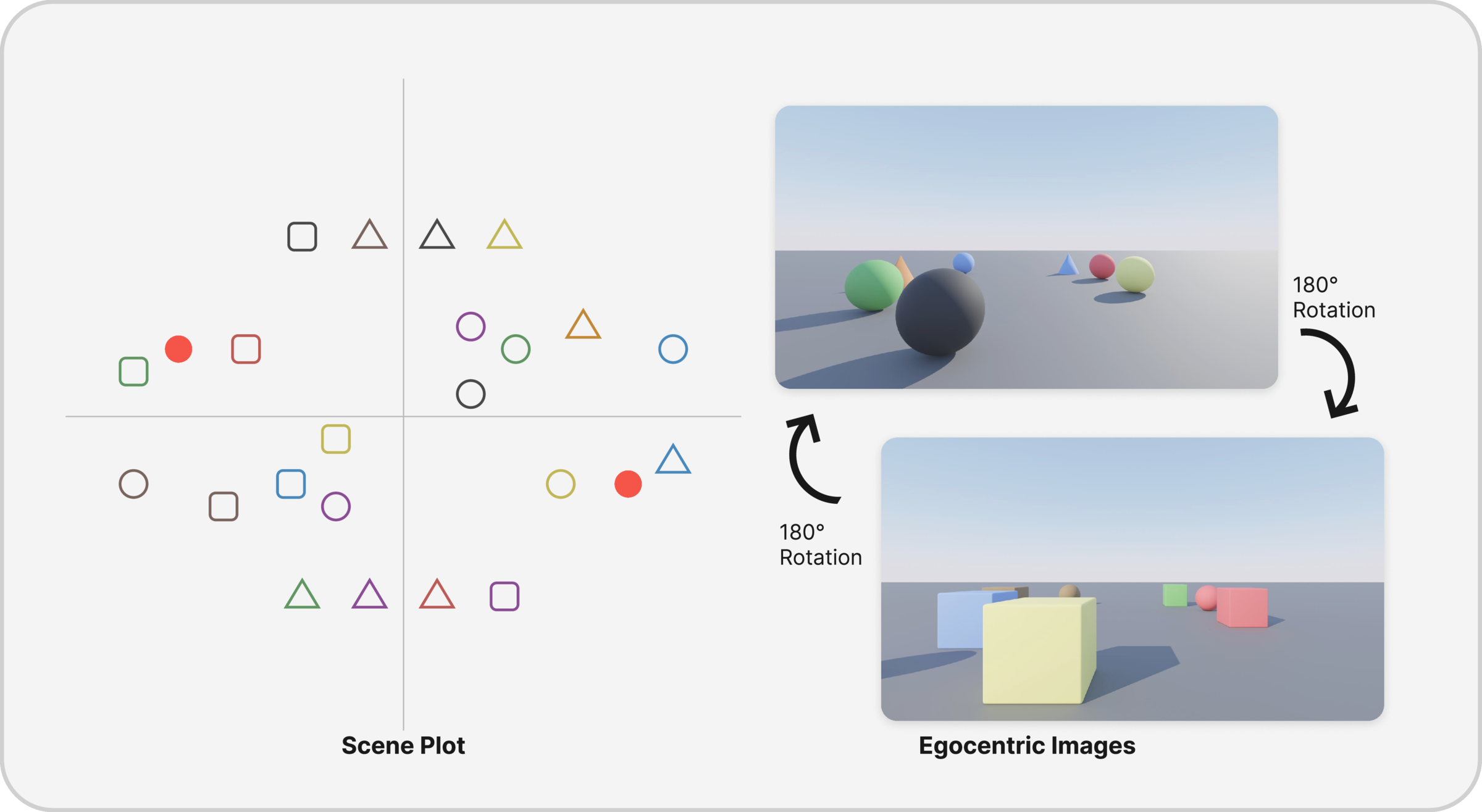
Full Rotation
360° rotation in a cluttered scene; 0° and 180° views appear similar but contain different object identities (with 1–2 intentional duplicates). Tests whether models integrate egomotion and context.
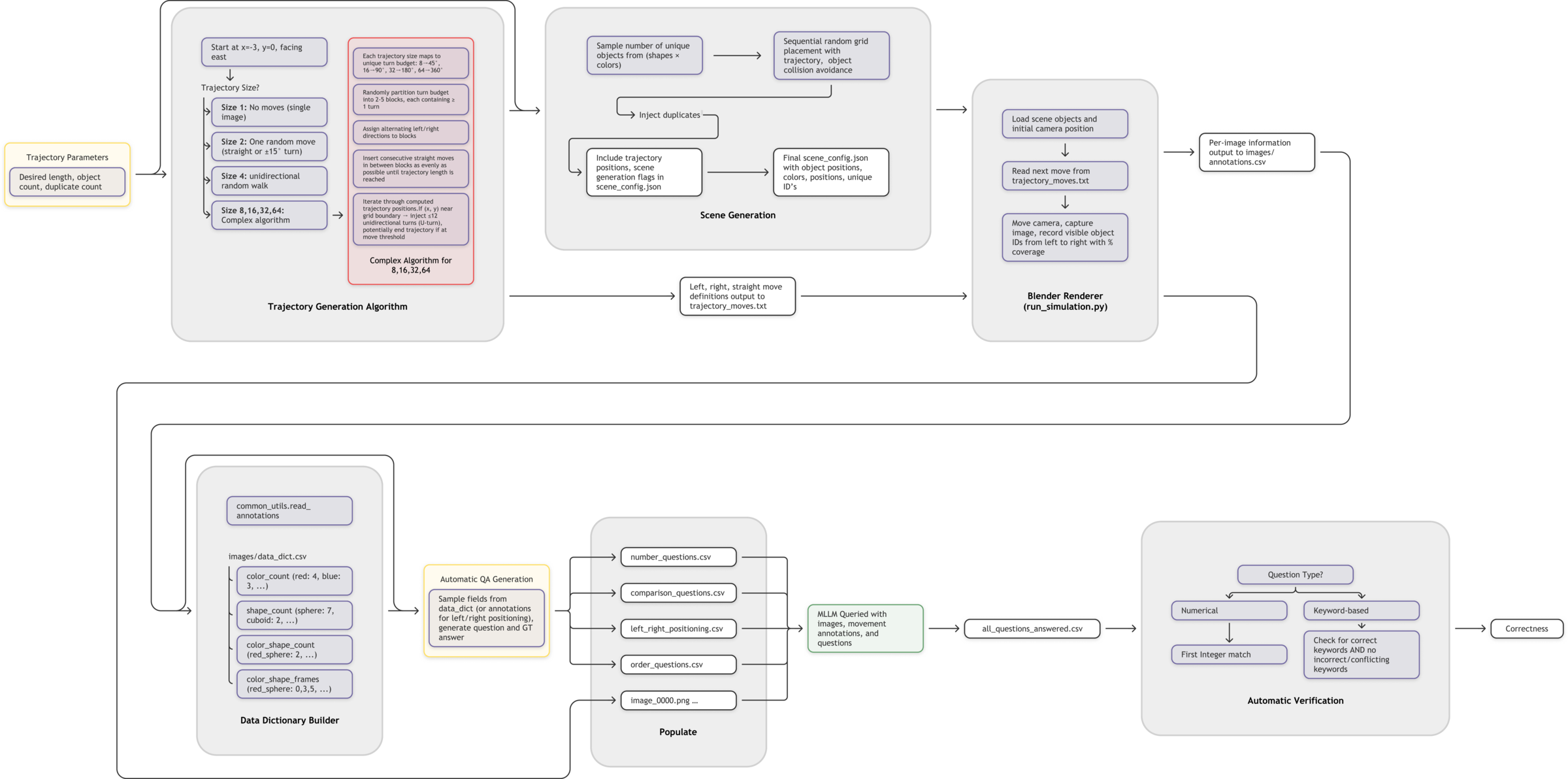
Generation & Verification
Per‑frame annotations (IDs, pixel coverage) power automated QA generation and a keyword‑aware verifier for grading.
Results
Reasoning models (e.g., o3) lead overall but still underperform humans—particularly on counting and comparison under viewpoint change, congestion, and duplicates.
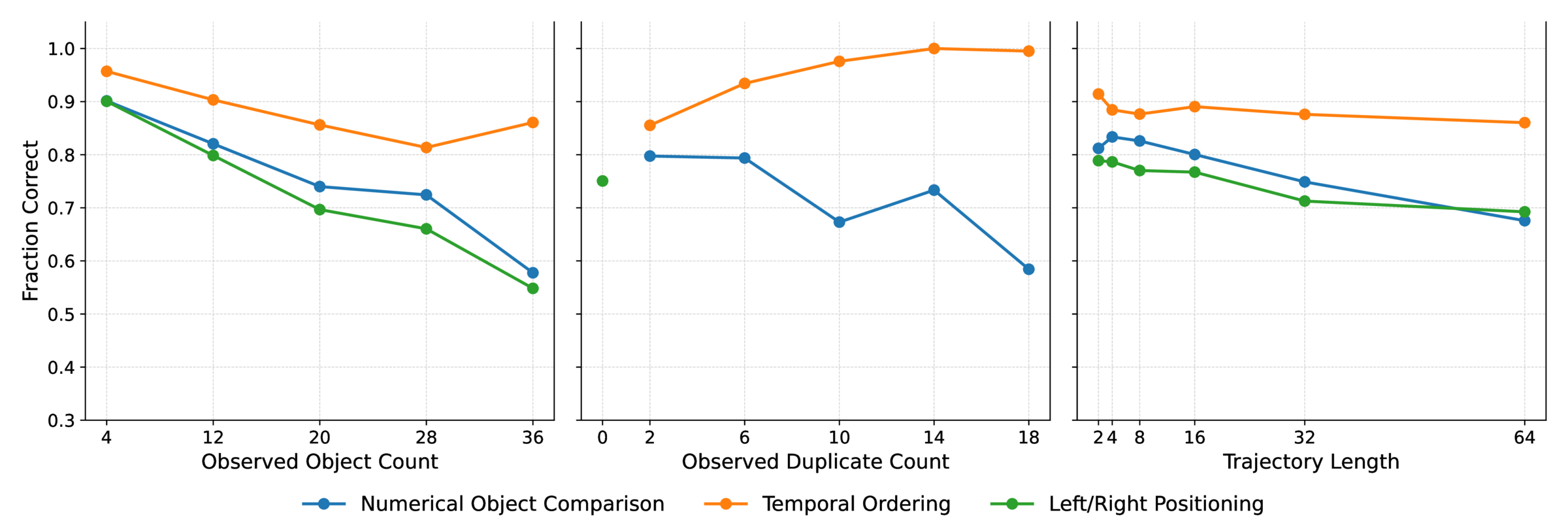
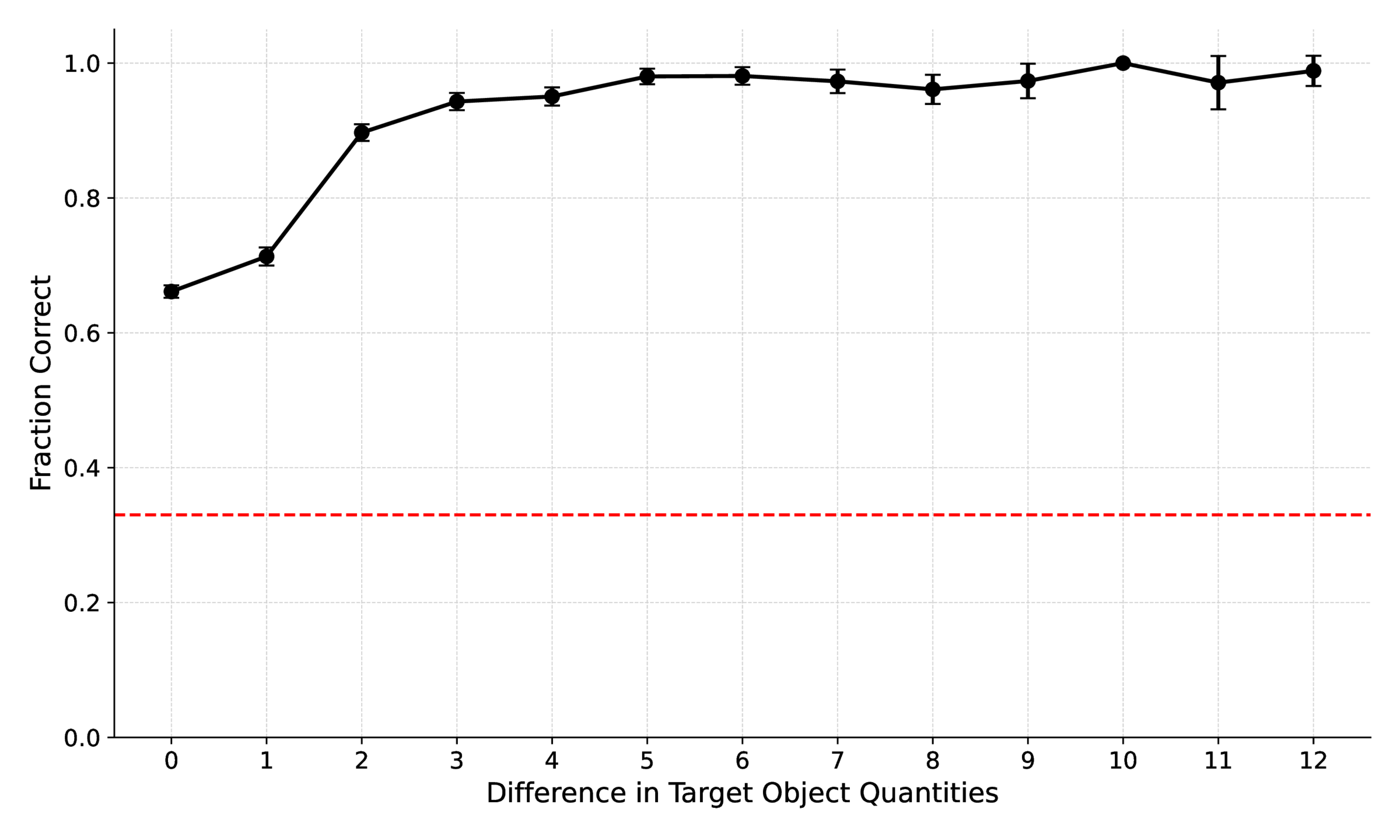
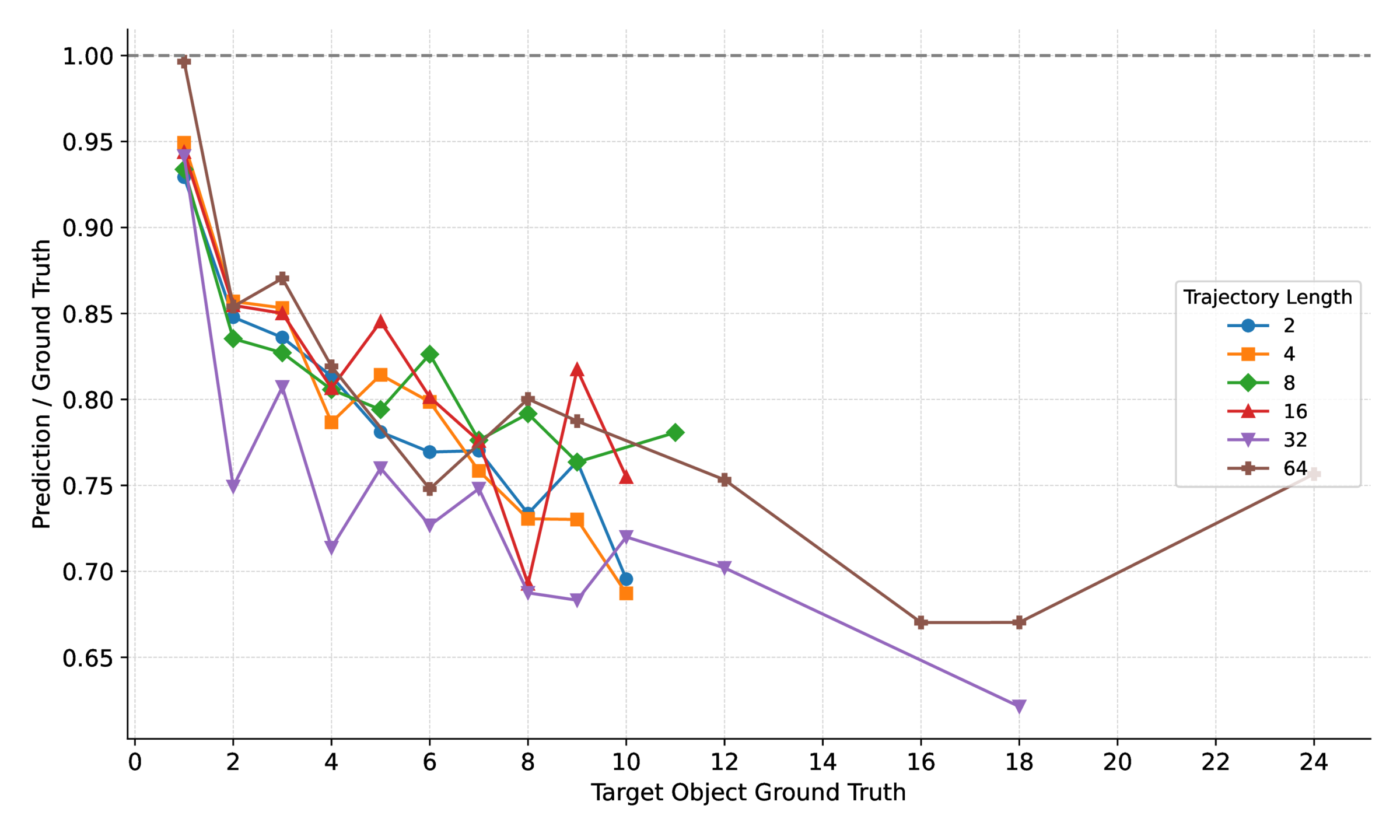
| Question Metrics | Overall | Num. Comparison | Left/Right Rel. | Temp. Ord. | Counting |
|---|---|---|---|---|---|
| Full Count | 47,019 | 15,580 | 1,576 | 14,304 | 15,559 |
| Mini Count | 154 | 39 | 38 | 37 | 40 |
| Random Chance | — | 33.3 | 50.0 | 33.3 | — |
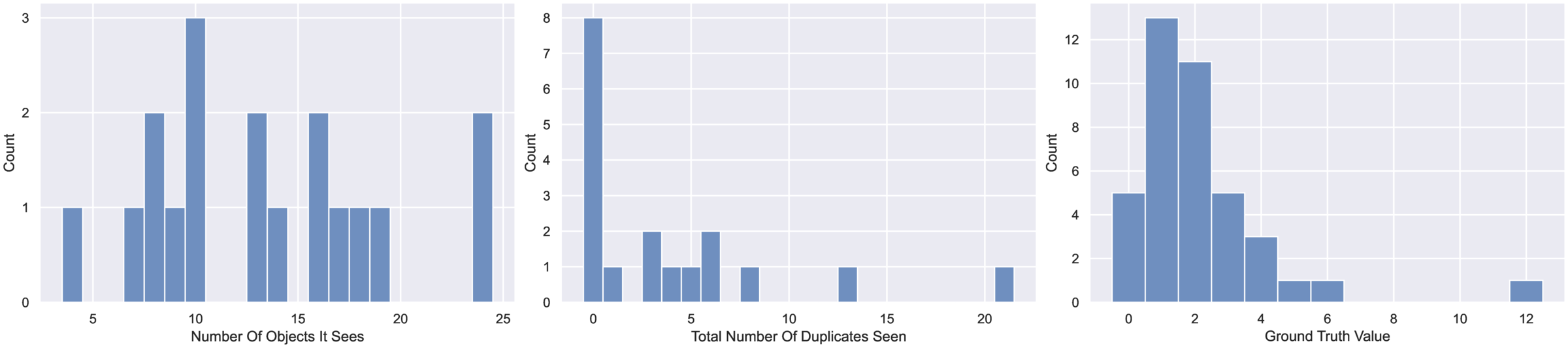
Selected Figures
BibTeX
@inproceedings{thompson2025rem,
title = {REM: Evaluating LLM Embodied Spatial Reasoning through Multi-Frame Trajectories},
author = {Jacob Thompson and Emiliano Garcia-Lopez and Yonatan Bisk},
booktitle = {Proceedings of COLM 2025},
year = {2025},
note = {Code and dataset: https://github.com/EmilianoGarciaLopez/REM}
}Acknowledgments
We thank Lockheed Martin Corporation, the DCIST Collaborative Research Alliance, and Fujitsu Limited for partial support.